Gallery
Frame-by-Frame Results
Video and frame comparisons from a real broadcast clip reframed by AI. Left: original 16:9. Right: AI-reframed 9:16.
Original Broadcast Video
16:9 1280 × 720
→
AI Reframe
AI-Reframed Vertical Output
9:16 720 × 1280
Original Broadcast Video
16:9 1920 × 1080
→
AI Reframe
AI-Reframed Vertical Output
9:16 1080 × 1920
Scene 1 — Reporter · Beijing
 16:9 1920 × 1080
16:9 1920 × 1080
16:9 1920 × 1080
→
AI Reframe
Reframed Output
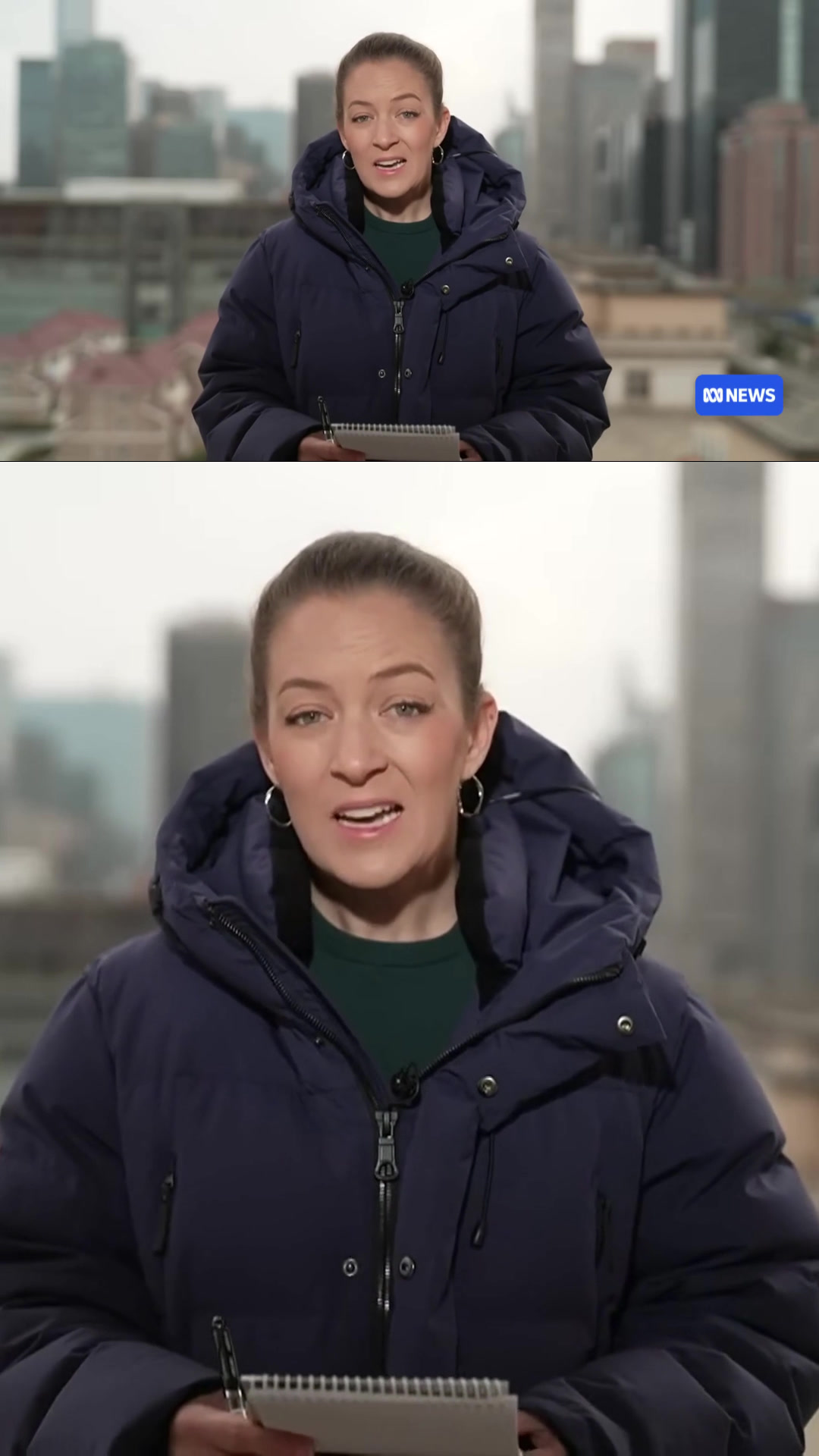 9:16 1080 × 1920
9:16 1080 × 1920
9:16 1080 × 1920
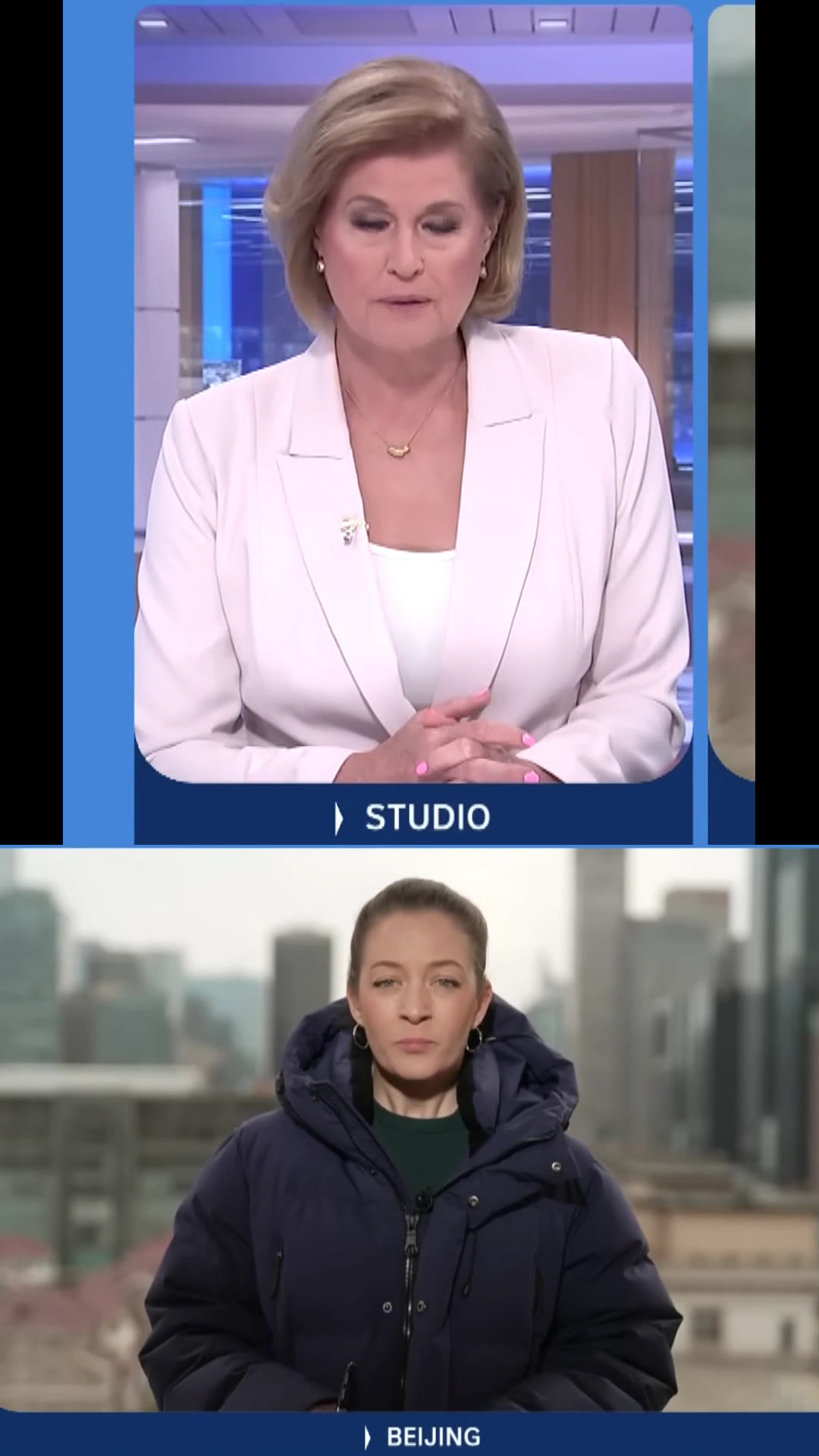
Scene 2 — Two-Anchor Split · Studio / Beijing
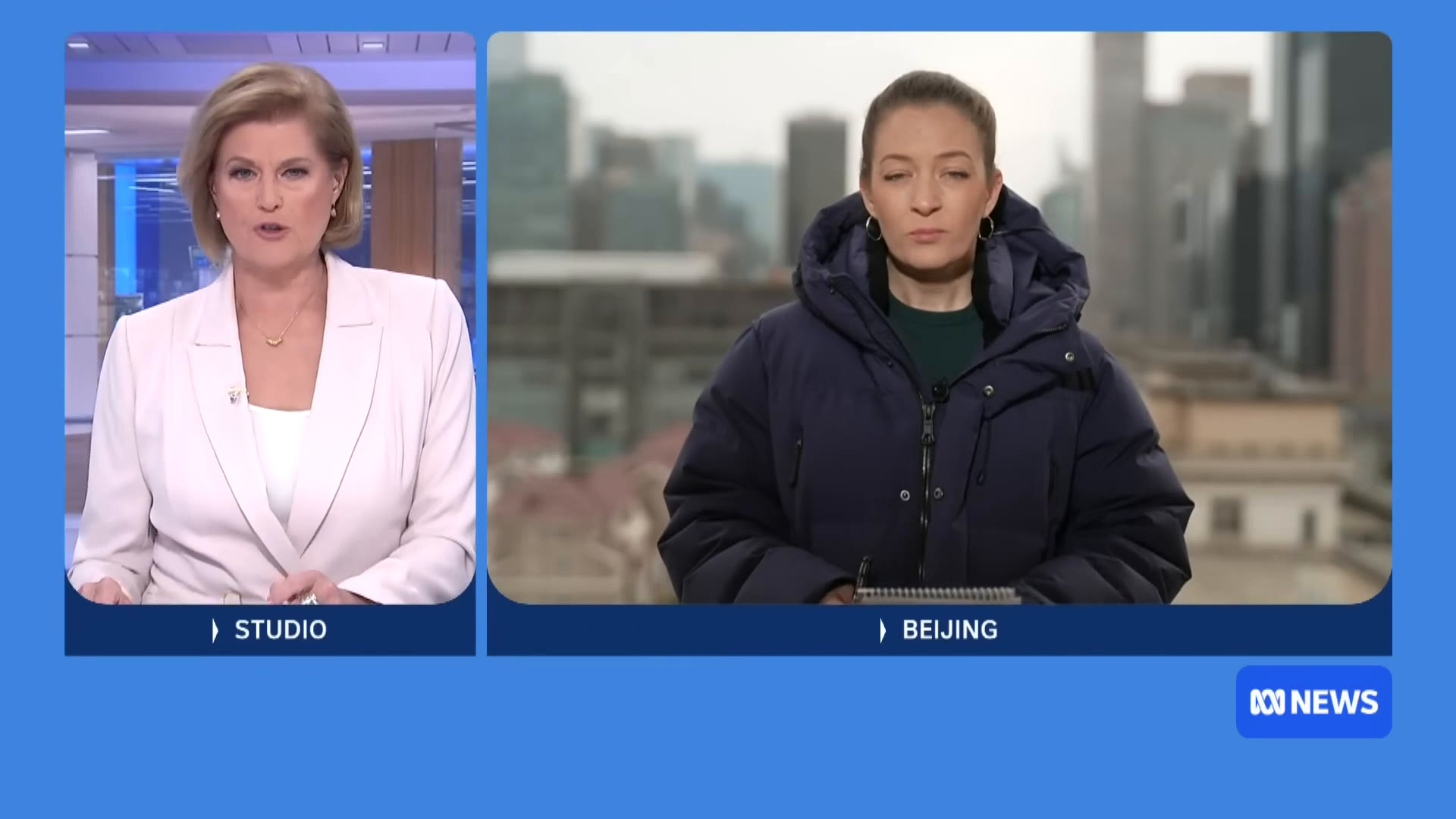 16:9 1920 × 1080
16:9 1920 × 1080
16:9 1920 × 1080
→
AI Reframe
Reframed Output
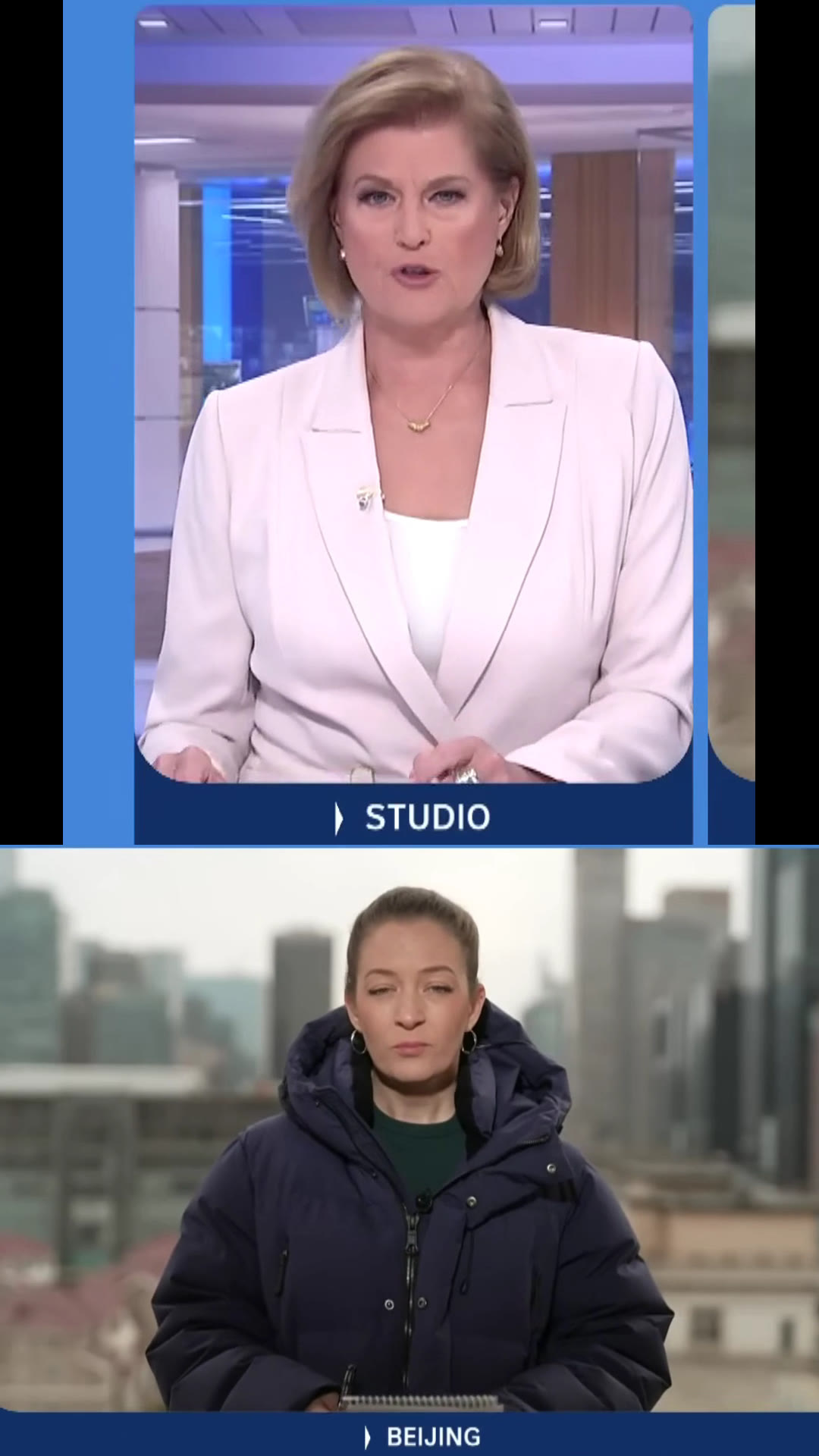 9:16 1080 × 1920
9:16 1080 × 1920
9:16 1080 × 1920
Scene 3 — Two-Anchor Split · Continuous
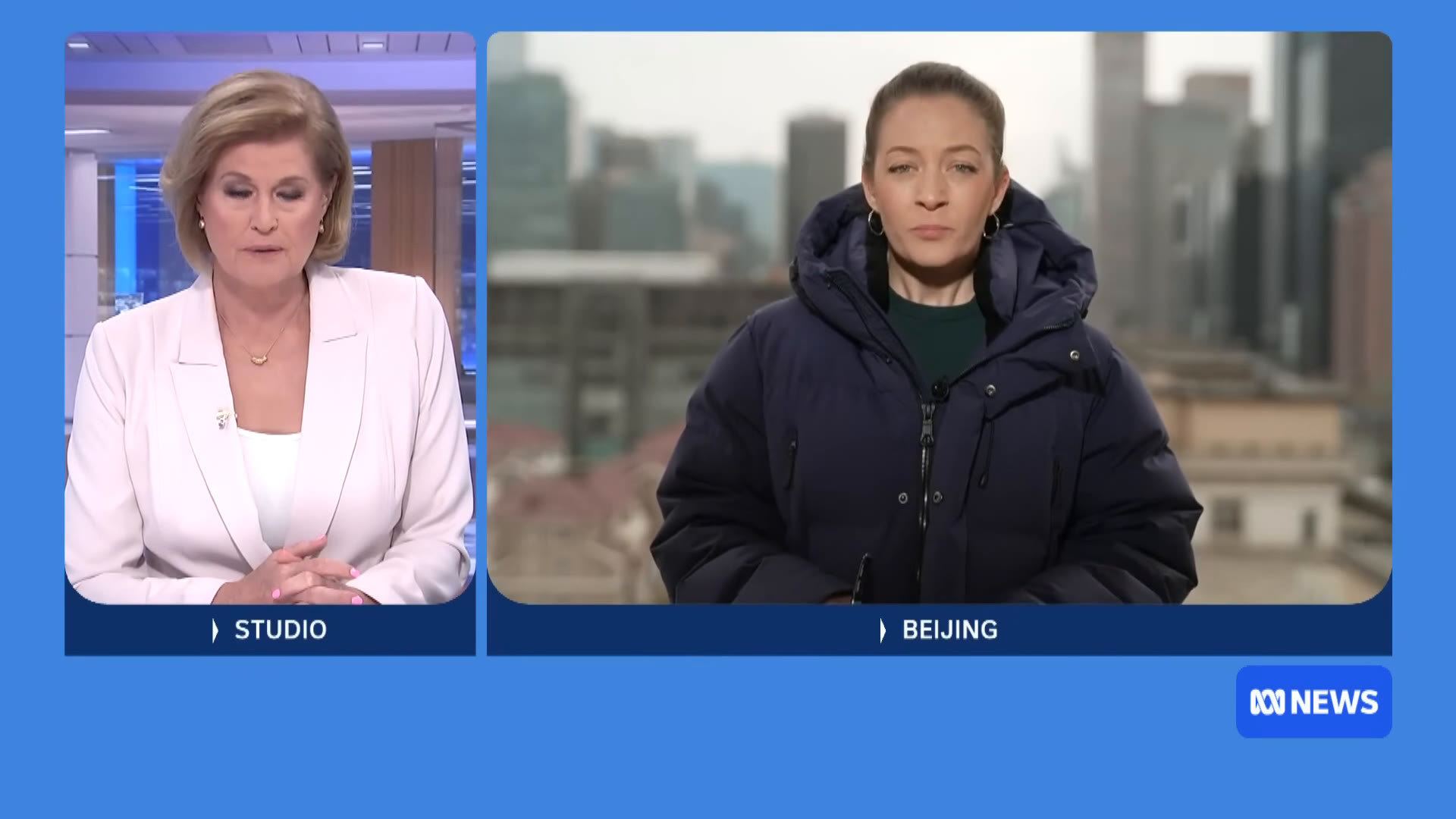 16:9 1920 × 1080
16:9 1920 × 1080
16:9 1920 × 1080
→
AI Reframe
Reframed Output
 9:16 1080 × 1920
9:16 1080 × 1920
9:16 1080 × 1920